Unveiling the Landscape of Generative AI and Language Models
Introduction
Welcome to the dynamic world of Generative AI and Language Models (LLMs)! In this comprehensive exploration, we will delve into the intricacies of Generative AI, Foundation Models (FMs), Prompt Engineering, LangChain, Vector Databases, Hallucinations, Reasoning, and Responsible AI. The landscape is evolving rapidly, and understanding these concepts is crucial for navigating the cutting-edge developments in AI and ML.
Chapter 1: Illuminating Generative AI
Evolution Beyond Discriminative AI
Historically dominated by discriminative AI, where models classify or forecast based on training data, the emergence of Generative AI marked a paradigm shift. Now, models can create new content, making strides in various industries like fashion, automotive, finance, healthcare, and more. Deep Learning and NLP have progressed from traditional models to sophisticated ones like GANs (Generative Adversarial Networks), contributing to Artificial General Intelligence (AGI).
Generative AI, a transformative field, gained significant momentum by enabling the creation of content using extensive pre-existing data. Beyond the realm of tech enthusiasts, it has democratized AI implementation, eliminating the necessity for non-tech individuals to learn programming. Coders and programmers benefit not only from code generation models but also from translation across programming languages. Researchers, however, face challenges in keeping pace with advancements. Automation is reshaping various job sectors, from call centers to content creation, with AI-generated voice assistants, 3D imaging, AR/VR, metaverse, robotics, and self-driving vehicles at the forefront.

Synthetic data creation for model training is another breakthrough, enhancing privacy by generating real-world-like data. Movies and visual editing have undergone a fascinating transformation with the advent of generative models, bringing possibilities like scene recreation from history, de-aging people in pictures, and altering backgrounds and attire. The landscape of AI has evolved to a point where models can summarize or generate questions from extensive texts, reducing the need for manual reading.
Democratization of AI
Generative AI has democratized AI implementation, making it accessible to non-tech individuals. Both coders and non-coders benefit from models generating code, translating programming languages, and aiding in content creation. While it simplifies tasks for some, researchers face challenges in keeping pace with advancements.
Chapter 2: Unveiling Foundation Models
Understanding Foundation Models
Foundation Models (FMs) represent a shift from traditional machine learning models. Trained on vast amounts of unlabeled data using self-supervised methods, FMs exhibit emergence and homogenization characteristics. OpenAI’s GPT-4, DALL-E2, and StabilityAI’s Stable Diffusion are notable FMs, revolutionizing tasks like text generation, translation, and code completion.
Building Foundation Models
To construct an FM like ChatGPT, a multi-step process involves pretraining the base language model on massive datasets sourced from the internet. The training, often spanning months on distributed GPUs, lays the foundation. Techniques like prompt engineering, supervised fine-tuning, reward modeling, and reinforcement learning enhance and fine-tune the base model.

Traditional machine learning models operate within the confines of supervised learning, trained on labeled data for specific tasks like image recognition or sentiment analysis. Foundation models, developed in recent years, diverge by training on vast amounts of unlabeled data through self-supervision or semi-supervision, making them adaptable to diverse tasks, both discriminative and generative. Coined by the Center for Research on Foundation Models (CRFM), these models exhibit emergence and homogenization, showcasing unexpected properties and applying the same method across domains.
Hyped foundation models include OpenAI’s GPT-4, Dall-E2, and StabilityAI Stable Diffusion. Building such models involves pretraining on large-scale data, predominantly from cloud service providers, and subsequent steps like prompt engineering, supervised fine-tuning, reward modeling, and reinforcement learning with human feedback. These models prove that training duration, rather than the number of parameters, significantly influences performance.
Chapter 3: Large Language Models in Focus
The Power of Large Language Models
Large Language Models (LLMs) are a subset of FMs, trained on massive text corpora, and have the capability to engage in human-like conversations. Transformer models, introduced by Google in “Attention is All You Need,” paved the way for LLMs like OpenAI’s GPT series, HuggingFace’s BLOOM, Google’s PALM2, and Meta AI’s LLAMA.
Large Language Models (LLMs), integral to foundation models, are trained on massive text corpora, often in the order of billions of parameters. Stemming from Google’s “Attention is All You Need!” and Transformer models, LLMs excel in understanding natural language, word meanings, and correlations. Notable models include OpenAI’s GPT series, HuggingFace BLOOM, Google’s PALM2, Meta AI’s LLAMA, and others from Cohere and AI24Labs. LLMs can be fine-tuned on small supervised datasets using Parameter Efficient Fine-Tuning (PEFT) to minimize computational and storage costs.
Fine-Tuning and Efficient Parameter Usage
Fine-tuning LLMs involves adapting them to specific tasks using domain-specific data. Parameter Efficient Fine-Tuning (PEFT) addresses challenges in fine-tuning, reducing computational and storage costs. Reward modeling and reinforcement learning with human feedback further optimize LLMs for complex tasks.
Chapter 4: The Art of Prompt Engineering
Unleashing the Power of Prompts
Prompt-based ML facilitates interaction with LLMs by describing tasks through prompts. Techniques like zero-shot prompting, few-shot prompting, Chain-of-Thoughts (CoT) prompting, and Self-Consistency enhance precision. Prompts serve as a vital tool for guiding LLMs in diverse applications, from code generation to text summarization.
Prompt-based machine learning facilitates interaction with LLMs by sending requests describing the intended task. Precise prompts yield better results, and various techniques like zero-shot prompting, few-shot prompting, Chain-of-Thoughts (CoT), Self-Consistency, and Tree-of-Thoughts have emerged. Fine-tuning LLMs with domain-specific data using prompt and completion formats remains effective, allowing adaptation to specific tasks.
LangChain: A Framework for Interaction
LangChain emerges as a powerful LLM framework, providing support for models from various labs. With modules like Model Hub, Data Connection, Chains, Agents, Memory, and Callbacks, LangChain simplifies LLM application development in both Javascript and Python environments.
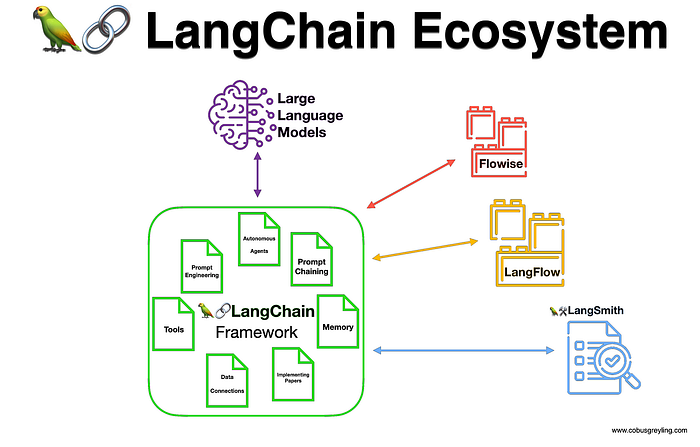
LangChain, a framework supporting LLM interactions, features modules like Model Hub, Data Connection, Chains, Agents, Memory, and Callbacks. With support from AI24Labs, Anthropic, Cohere, HuggingFace, OpenAI, and others, LangChain simplifies LLM application development. Its capability to process and organize information from documents, aided by vector databases and embeddings, enhances context preservation.
Chapter 5: Harnessing Vector Databases and Embeddings
Efficient Data Storage and Retrieval
Vector databases, optimized for high-dimensional vector storage, play a crucial role in LLM applications. Platforms like Milvus, Pinecone, and FAISS enable efficient storage and retrieval, supporting tasks such as image and document searches based on vector distances.
Embeddings: Bridging Complexity and Understanding
Embeddings convert complex data types into numeric representations, aiding deep neural networks in understanding and processing data. The advantages include dimensionality reduction, semantic relationship capture, and support for tasks like recommendation systems and text classification.
Vector databases, optimized for storing and retrieving high-dimensional vectors, are employed to store LLM-generated vectors efficiently. Implementations like Milvus, Pinecone, Weaviate, Annoy, and FAISS enable quick retrieval of domain-specific data. The structured representation of data in mathematical vectors allows for efficient similarity searches and handling of diverse data types, contributing to tasks like recommendation systems, text classification, information retrieval, and clustering.
Chapter 6: Navigating Hallucinations and Grounding
Addressing LLM Hallucinations
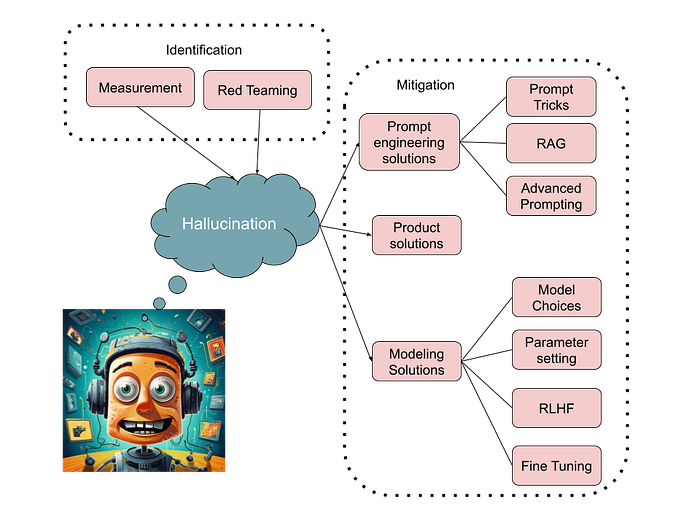
LLMs often produce hallucinatory outputs due to factors like overgeneralization, lack of contextual understanding, biased training data, and encountering rare inputs. Techniques like fine-tuning, adversarial testing, and transparent model explanations are employed to mitigate hallucination risks.
Grounding LLMs for Reliability
Grounding LLMs is crucial for reliable outputs. Reinforcement learning with human feedback, external knowledge incorporation, and fact-checking mechanisms contribute to grounding strategies. Ongoing research explores ways to enhance contextual understanding and reasoning abilities.
LLMs are prone to hallucinations, generating answers that may seem plausible but are incorrect. Causes include overgeneralization, lack of contextual understanding, biased training data, and encountering rare or out-of-distribution inputs. Grounding LLMs remains a challenge, and techniques like reinforcement learning with human feedback and fact-checking from other LLMs aim to mitigate hallucinations. Ongoing research emphasizes the need for diverse and representative training data, adversarial testing, and transparent model explanations.
Chapter 7: Introducing SocraticAI for Reasoning
Multi-Agent Collaborative Problem Solving
SocraticAI introduces multi-agent collaboration, involving analysts like Socrates and Theaetetus, and a proofreader Plato. This collaborative role-play framework, built on ChatGPT 3.5, incorporates WolframAlpha and Python code interpreter for problem-solving. SocraticAI aims to bring reasoning to LLMs in mathematical and logical tasks.
SocraticAI introduces reasoning to LLMs through Multi-Agent Collaborative Problem Solving. Utilizing three agents — Socrates, Theaetetus, and Plato — in a role-play format, it incorporates WolframAlpha and a Python code interpreter. SocraticAI aims to enhance reasoning in logic-based tasks and offers a structured approach to problem-solving. Key features include question generation, dialogue management, domain knowledge incorporation, adaptive learning, and feedback/evaluation mechanisms.
Chapter 8: Pioneering Responsible Generative AI
Mitigating Risks and Ensuring Ethical AI
Generative AI introduces risks such as biased outputs, data privacy concerns, and misinformation spread. Responsible AI practices involve understanding potential risks, establishing ethical guidelines, transparent model explanations, bias detection, user control, and ongoing monitoring. Collaboration within the AI community and adherence to ethical standards are crucial for responsible AI development.
Conclusion
As we navigate the expansive landscape of Generative AI and LLMs, we witness the transformative power of technology. From the evolution of discriminative AI to the rise of Foundation Models, the art of prompt engineering, and the challenges of hallucinations, responsible AI practices guide us toward ethical and sustainable development. With continuous advancements, collaborative efforts, and a commitment to responsible AI, we shape a future where generative models contribute positively to society.
